In a Nutshell
Building AI infrastructure should incorporate both an AI-first infrastructure philosophy, which supports the operational logic of LLM-based systems, and a necessary degree of technological independence that allows for the flexible selection and replacement of technologies as needs evolve. Key tools to implement in this process include Ray Serve (acting as an intelligent router), vLLM (a next-generation inference engine), and MAX (an engine for the Mojo language, designed specifically for AI). Efficient GPU utilization is achieved through KubeRay, Gang Scheduling, and OpenCost. To avoid vendor lock-in, the solution utilizes Crossplane—a controller that enables resource management across different cloud providers via a unified API—as well as the integration capabilities of the Modular MAX Engine (MAX). All of these tools form the foundation of Cloud for AI, a proprietary solution from OChK.
One of the most common mistakes when implementing AI systems is treating them as a simple extension of existing infrastructure. In reality, infrastructure built for AI, especially for systems based on large language models (LLMs), follows a completely different logic. It’s not just about the right models or data—it’s about building a foundation that can keep up with rapid innovation, handle highly dynamic workloads, and provide full visibility and control over what’s happening under the hood.
So how do you build infrastructure that can meet the unique demands of AI systems? In this article, we’ll walk you through key design principles and technologies that can help you create an architecture that’s truly AI-ready—built to support the next generation of intelligent applications.
This is the third part of our Cloud for AI series, where we explore what it takes to build modern, secure, and compliant AI solutions in the cloud. In previous articles, we looked at where to develop AI projects and what tools to use. We also introduced the concept of Cloud for AI and key architectural guidelines that help you build in line with regulations like the AI Act and GDPR.
More insights are on the way—follow us on LinkedIn so you don't miss the next part!
What Makes Infrastructure AI-Ready?
Building infrastructure for artificial intelligence systems isn’t the next evolutionary step of traditional IT—it’s a full-scale shift in how we design and secure environments. That’s because AI workloads bring a completely new set of challenges: unpredictable usage spikes, the need for real-time scalability, constantly evolving model ecosystems and libraries, ultra-low latency requirements, and strict control over both models and data.
Another common pitfall for organizations implementing AI is vendor lock-in—becoming dependent on a single technology provider. In the AI space, this kind of dependency tends to get costly over time—not just financially, but also in terms of flexibility and modernization. That’s why AI infrastructure should be designed to minimize these constraints from the start.
OChK’s Cloud for AI is built on a core design principle: almost every component is replaceable. This means individual infrastructure elements can be added, removed, or swapped out—without rebuilding the entire system from scratch. Think of it like a box of LEGO bricks: if every piece has standard connectors, it can easily be replaced with another that serves the same purpose.
For example, if you’re currently using vLLM as your inference engine and a faster alternative appears six months from now, Cloud for AI lets you integrate it without touching the rest of the system. This kind of modularity is essential in environments where model lifecycles are measured not in years, but in months—or even weeks.
Cloud for AI supports both open-source and commercial technologies, giving teams the freedom to mix and match tools and services to fit their needs. Not only does it boost operational flexibility, but also helps organizations move faster and build competitive advantage in a world where AI innovation is measured in weeks, not quarters.
Below, you’ll find an overview of selected tools and best practices used in Cloud for AI—elements that can serve as the foundation of a well-designed infrastructure for artificial intelligence systems.
The Philosophy Behind AI-First Infrastructure
Traditional infrastructure thinking treats artificial intelligence as just another type of workload—something that can be handled like any other compute task. But this approach quickly breaks down, especially when serving models to large numbers of users. AI systems generate highly specific types of demand that don’t follow familiar patterns.
To begin with, AI-first doesn’t just mean running large models. It means designing infrastructure to support the way they operate—planning, reasoning, and executing tasks in real time, particularly when working with large language models (LLMs). As soon as agents enter the picture—models that orchestrate other tools—and reasoning techniques like Chain-of-Thought, Tree-of-Thought, ReAct, or SARSA-RLHF are involved, the system faces entirely new workload vectors and challenges that must be accounted for at the architecture level.
AI workloads are not steady. They follow a burst compute pattern—models might sit idle for hours, then suddenly demand teraflops of processing power in a matter of minutes. Traditional infrastructure often can’t handle this efficiently: it either over-provisions and wastes resources, or under-provisions and fails to respond to spikes. The challenge grows when agents come into play. A single cycle (plan → tool → observe → adjust) can involve dozens of steps, each acting like a mini workload surge on its own.
Unlike classic applications where compute and memory can be scaled independently, AI workloads require tight memory-compute coupling. A 70-billion-parameter model doesn’t just need enough GPU power—it needs high-bandwidth memory. And it’s not just model memory: each agent also has its own state to store—context, plans, reasoning paths, results.
Another critical factor is latency sensitivity. The difference between 50 and 500 milliseconds can determine whether a system feels usable. Real-time responses require not just fast GPUs, but a carefully optimized execution path—from request to response.
Finally, both the models and the data they process act as gravity wells. Transferring terabytes of model weights between locations is both expensive and time-consuming. That’s why architecture must take the physical location of models and data into account when making deployment and scaling decisions. Another important factor is state gravity—agents generate and consume dynamic states, such as episodic memory or caches of intermediate planning steps, which must also be placed and managed deliberately.
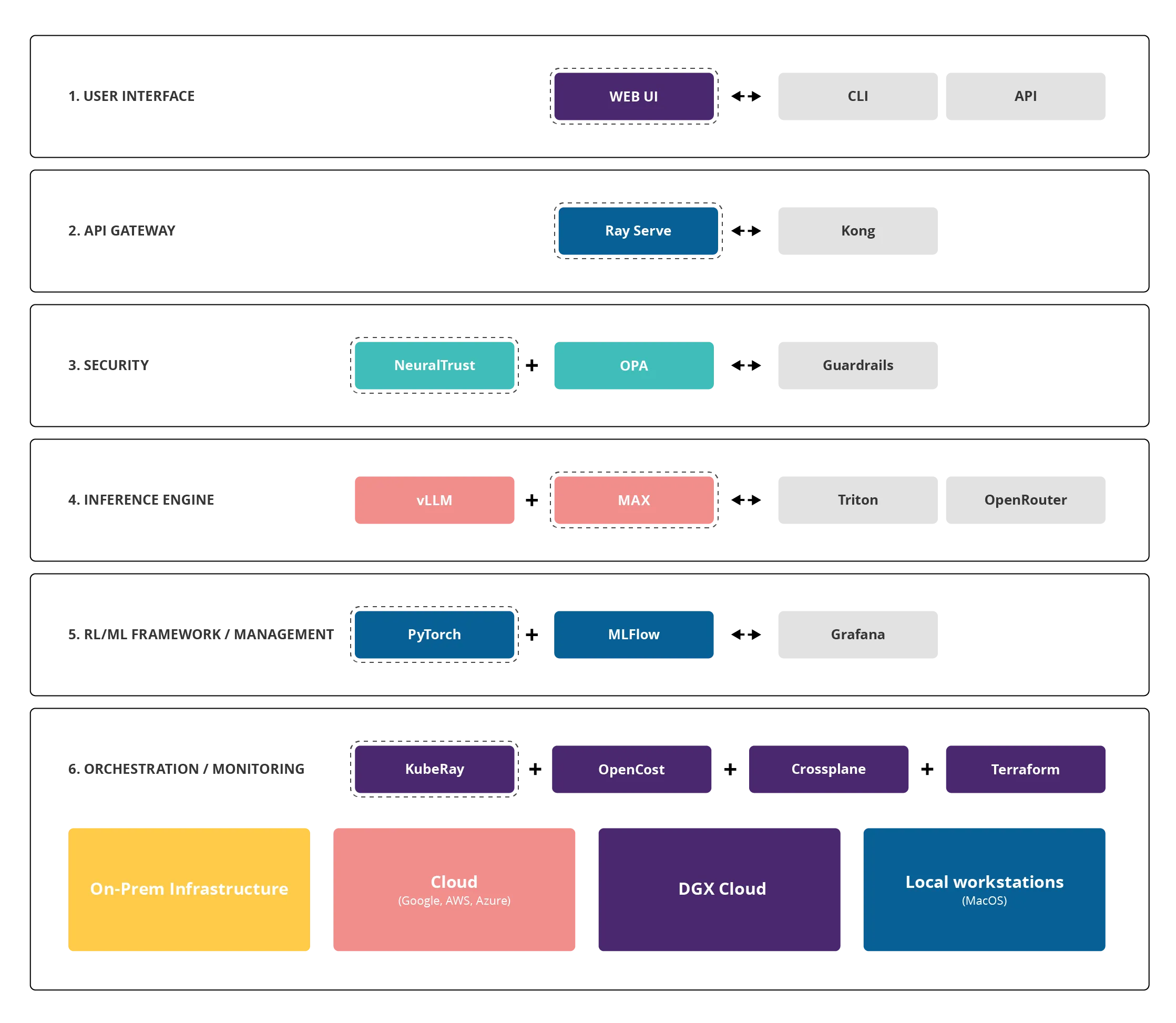
Fig. 1: Cloud for AI Architecture
The Inference Layer: The Heart of the System
The inference layer is where the magic happens—where AI models actually generate responses. Cloud for AI uses a set of key technologies here:
- Ray Serve acts as an intelligent request router. Think of it like an experienced dispatcher in a call center—it receives incoming queries and forwards them to the right subsystem. Crucially, Ray Serve tracks system load and automatically spins up additional model instances when traffic increases. If P95 latency (the response time for 95% of queries) exceeds 150 milliseconds, the system scales up on its own.
- vLLM (Versatile Large Language Model) is a next-generation inference engine. It uses a technique called PagedAttention to manage GPU memory more efficiently. Imagine your GPU as a fast but limited warehouse—vLLM reorganizes it so cleverly that it effectively triples its capacity. The result? A Llama-3 70B model can generate over 1,000 tokens per second—that’s a full page of text in the blink of an eye.
- MAX (Modular Accelerated Xecution) is an engine built for Mojo, a programming language designed specifically for AI. MAX shines in tasks that require custom optimization and performs especially well in multi-node configurations. It’s also compatible with Python, so existing Python code runs out of the box.
- Triton is also available—for traditionalists who rely on solutions from NVIDIA 😉
Intelligent Resource Management
Graphics processing units (GPUs) are the most expensive component of AI infrastructure. A single H200 or H100 card can cost tens of thousands of euros. That’s why Cloud for AI treats GPUs as a critical resource that must be used as efficiently as possible. To achieve this, the platform relies on several key technologies:
- KubeRay introduces a breakthrough concept: GPU sharing. Instead of assigning a full GPU to a single task (which might only use 25% of its capacity), the system can split the GPU across multiple workloads.
- Gang Scheduling ensures that all parts of a distributed task start at the same time. This is essential for large models that are split across multiple GPUs. Without gang scheduling, some GPUs might sit idle waiting for others—wasting valuable resources.
- OpenCost provides real-time, detailed cost analysis. Every namespace (a logical resource group) gets its own live cost meter. Managers can see exactly how much a single model query, training run, or operation is costing—like a taximeter for AI infrastructure.
The Data Pipeline: From Raw Input to a Working Model
Turning raw data into a production-ready AI model is more than a technical task—it’s a coordinated process, much like an assembly line where every step matters. The example below illustrates a typical pipeline, highlighting how even seemingly simple deployments involve many moving parts. The tools mentioned at each stage are just examples. As with all things Cloud for AI, the core idea remains: you can mix and match modular components—just like LEGO bricks—to fit your specific needs.
1. Ingest. Vector.dev replaces traditional tools like Fluent-Bit and adds support for WASM-based transformations, allowing data to be cleaned and reshaped as it’s ingested.
2. Validate. Great Expectations checks data quality and enforces contracts—rules the data must follow (e.g., “age must be a number between 0 and 150”). Data that violates these contracts gets rejected.
3. Commit. LakeFS creates immutable snapshots of datasets. Each version is given a unique ID, making it easy to roll back to a known data state at any time.
4. Feature Engineering. Kubeflow Pipelines orchestrates the transformation of raw data into model-ready features. It’s like prepping ingredients before cooking—data is cleaned, normalized, and combined into usable inputs.
5. Training. KubeRay handles distributed training across multiple GPUs. Large models are automatically partitioned, and the system keeps training jobs in sync.
6. Governance. Credo AI and AI Verify run ethical testing and generate compliance reports. Each model gets a kind of “passport” that documents its origin and key attributes.
7. Package. Models are compiled using Mojo/MAX and digitally signed using Cosign. This ensures that the model in production is exactly the one that passed testing.
8. Serve. Ray Serve exposes the model via an API, automatically scaling the number of instances based on traffic.
9. Observe. The system monitors performance metrics, detects data drift, and alerts teams to anomalies.
Multicloud as the Standard
By now, it’s clear that vendor lock-in is one of the biggest challenges in today’s IT landscape. Cloud for AI uses Crossplane—a powerful control plane that lets you manage resources across multiple cloud providers through a unified API.
In practice, this means you can use the same YAML manifest to spin up a GPU cluster on AWS, Azure, Google Cloud, or NVIDIA’s GDX Liptron. Migrating between providers comes down to changing a few parameters—not rewriting the entire system. This gives you true independence and serious negotiating power when dealing with cloud vendors.
MAX Engine: A Game Changer
In this context, it’s worth highlighting the role of the Modular MAX Engine—one of the core components of Cloud for AI.
CUDA (Compute Unified Device Architecture) has effectively become an industry standard, but that also means near-total dependence on NVIDIA. MAX breaks that monopoly by compiling models into a universal intermediate representation, which can then be optimized for virtually any hardware:
- NVIDIA GPUs (no need for CUDA),
- AMD GPUs (with native ROCm support),
- Intel GPUs and Gaudi accelerators,
- Apple Silicon chips,
- and even more exotic hardware like Cerebras or Graphcore.
What’s more, MAX often outperforms native implementations. How? Because it enables advanced optimizations that general-purpose frameworks like PyTorch simply can’t do:
- kernel fusion across entire model graphs,
- elimination of unnecessary memory copies,
- hardware-specific tuning (e.g. using tensor cores or matrix units).
Importantly, this abstraction layer doesn’t come at the cost of performance. MAX proves that portability and efficiency aren’t mutually exclusive.
Summary
The way you design your AI-ready infrastructure has a direct impact on the effectiveness of the solutions you build. That’s why it’s essential to understand how this kind of environment differs from traditional systems—and which technologies and design principles are needed to meet the unique demands of artificial intelligence.
Cloud for AI, built by OChK experts on top of the OChK Stack, represents a fundamental shift in how infrastructure is approached. It’s designed from the ground up with AI in mind: modular, hardware-agnostic, and fully compatible with both open and commercial technologies. It avoids vendor lock-in, gives you control over costs, and ensures compliance with regulatory frameworks like the AI Act—all while keeping your data secure. And it works anywhere: from local workstations, to your own data center, to the public cloud. That means you can plan precisely, scale predictably, and keep full visibility at every stage of deployment.
Got questions about building AI-ready infrastructure? Want to discuss your own plans for AI adoption or learn more about Cloud for AI? Let’s get in touch—we’re happy to help!