Dzisiejsze systemy informatyczne osiągnęły rozmiary, o jakich jeszcze 15 czy 20 lat temu nikt nie mógł marzyć. Zarządzanie nimi nie byłoby możliwe bez automatyzacji zarządzania serwerami, konteneryzacji aplikacji oraz… chmury, która pozwala szybko zwiększać skalę działania. Obecnie technologia Kubernetes czerpie z wcześniej rozwijanych koncepcji i w inteligentny sposób łączy je, dzięki czemu jeden administrator może zarządzać aplikacją, która dwie dekady temu potrzebowałaby do obsługi całego działu IT.
Klasyczny model administracji usługami IT ukształtował się na przełomie lat 80. i 90. XX wieku. Miał kilka charakterystycznych cech:
- bardzo wysoki koszt posiadania - jeden serwer kosztował co najmniej 50 tys. USD.
- jedna aplikacja - jeden serwer fizyczny - ponieważ serwery były drogie i brakowało narzędzi umożliwiających przenoszenie aplikacji, to zazwyczaj spędzały one całe “życie” na jednym serwerze.
- długi czas życia aplikacji - raz skonfigurowana i uruchomiona nie była modyfikowana przez lata. Zmiany, migracje, czy wymiana sprzętu oznaczały wysokie koszty i stracony czas.
- jedna aplikacja - jeden administrator - administratorzy posiadali “wiedzę tajemną”, którą nie chcieli się dzielić z otoczeniem, ograniczony był dostęp do literatury czy serwerów testowych.
- brak przenaszalności - brak powszechności rozwiązań IT i standardów w branży powodował, że pojedyncze osoby rozwijały własne rozwiązania pod potrzeby danej organizacji.
- brak open source - trzy dekady temu prawie całe oprogramowanie było zamknięto-źródłowe i kontrolowane przez niewielką grupę podmiotów. Co prawda istniał freeware, ale często bez kodu źródłowego. Brakowało też narzędzi do powtarzalnego i bezproblemowego jego uruchamiania.
Rewolucja: Git, Github i pull request
Zmiany status quo w utrzymaniu i rozwijaniu platform i aplikacji rozpoczęły się w latach 2005-2008. Pierwszym krokiem było powstanie Gita (2005 r.), a na jego podstawie Githuba (2008 r.). Dzięki niemu programiści mogą pracować lokalnie i tylko w momencie aktualizacji łączą się z serwerem. Github spopularyzował i zautomatyzował też pull request, czyli dokładny opis i możliwość publikacji zmiany, która uzyskuje własny URL. Dzięki temu można podzielić się linkiem, a nie plikiem zmian. To rewolucja w zarządzaniu kodem, która przyspieszyła prace nad aplikacjami, a także rozwój środowiska open source.
Git, Github i pull request to nowoczesne mechanizmy pracy z kodem, ale hamulcem rozwoju był wciąż system operacyjny. Stopień jego komplikacji (zarówno konfiguracja, jak i dalsze utrzymanie) powodował, że systemy i aplikacje dalej działały w modelu: jeden admin - jedna aplikacja - jeden serwer.
Automatyzacja OS
Początek automatyzacji IT zaczął się od rewolucji w Amazonie, tzw. API mandate, który zrezygnował z przesyłania danych plikami CSV w e‑mailach. Wszystkie dane są przesyłane za pomocą API. Następnie wewnętrzne usługi hostingowe zostały udostępnione na rynku i tak powstała chmura publiczna Amazon. Rozpoczęła się nowa era w IT, w której ceny fizycznych serwerów szybko spadały, ale coraz mniej firm chciało je kupować.
Dzięki spadkowi cen i możliwości dzierżawienia setek maszyn administratorzy pojedynczej aplikacji musieli zarządzać nawet stukrotnie większą infrastrukturą. W efekcie problemy z zarządzaniem systemami operacyjnymi nasiliły się.
Jedną z pierwszych firm, która starała się już w 1993 roku rozwiązać problem skalowalności instalacji i zmian w OS‑ie był CFEngine. W 2005 r. powstał konkurent - Puppet. Dzięki tego typu rozwiązaniom zapisujemy za pomocą kodu docelowy stan systemu operacyjnego, a aplikacja wykonuje zaplanowane komendy.
To były początki ruchu DevOPS: istniał już Git i API, pojawiło się rozwiązanie, które załatwia sprawę szablonów konfiguracji i OS‑a. Czas przyjrzeć się niższym warstwom, czyli zarządzaniu warstwą przechowywania danych i samym sprzętem.
Wirtualizacja serwerów
Sama rewolucja API byłaby niewiele warta, gdyby nie zmiana koncepcji zarządzania sprzętem. W chmurze idea posiadania serwera fizycznie została zamieniona na jego dzierżawę. Ale zrealizowanie usługi, która na tym samym sprzęcie żongluje wieloma klientami, nie jest łatwe.
Znów powracał problem tzw. OS provisioningu, czyli jak szybko przygotować nowemu klientowi maszynę z pustym systemem operacyjnym. Wyzwanie to istnieje w modelu dzierżaw bare-metal (fizycznego sprzętu), jak i Virtual Machine (maszyn wirtualnych, w których dostajemy tylko ułamek fizycznego sprzętu).
Wirtualizacja serwerów polega na uproszczeniu dzielenia się sprzętem fizycznym oraz migracji OS‑a z jednego serwera fizycznego do drugiego. Nie wszyscy użytkownicy potrzebują całego serwera, wielu wystarczy jego “kawałek”. Wirtualizacja ułatwia taki podział serwera.
Aby umożliwić wirtualizację pomiędzy sprzętem fizycznym, a zwirtualizowanymi serwerami pojawił się nowy komponent - hypervisor. Jest to małe oprogramowanie, które żongluje maszynami wirtualnymi i ich dostępem do sprzętu fizycznego tak, żeby było wrażenie współbieżności przetwarzania. Hypervisor pozwala zwirtualizować elementy składowe serwera i zapisać tak zwirtualizowaną maszynę w jednym pliku, który można dowolnie przenosić pomiędzy serwerami fizycznymi.
W okresie rozwoju VM prędkości łącz internetowych były o wiele niższe niż obecnie, a plik z kopią obrazu zajmował nawet kilkadziesiąt gigabajtów. Dużo czasu zajmowało jego przesłanie i uruchomienie na serwerze. Aby rozwiązać ten problem powstały kontenery.
Konteneryzacja
Aplikacje typu config management pozwalały na zarządzanie większą flotą serwerów, rosła skala projektów, ale rozmiar plików powodował stratę czasu w oczekiwaniu na uruchomienie VM‑ek. Po raz kolejny trzeba było szukać nowego rozwiązania.
W 2008 roku miały miejsce dwa ważne wydarzenia: w kodzie źródłowym Linuksa pojawił się koncept namespace, a następnie na podstawie tego rozwiązania, przy wsparciu Google powstał jednych z pierwszych silników kontenerowych: LXC.
Zapomniany już z nazwy startup, któremu skończyły się pieniądze opublikował na Githubie swój cały kod źródłowy wraz z notką: “namespace są bardzo obiecujące, na pewno coś fajnego z tego kiedyś będzie, załączamy kod w języku Bash tworzący kilka namespace naraz”. Zauważył to inny startup, dotCloud. Z pomocą funduszy venture capital, z toczącymi się równolegle pracami nad LXC, oraz przy użyciu nowego wówczas języka golang, z popiołów poprzedniego eksperymentu powstał Docker.
“Wynalezienie kontenerów” jako idei izolacji systemu operacyjnego w 2008 roku nie było czymś zupełnie nowym, bo już w 2005 roku ujrzał światło dziennie produkt Solaris Zones. Ale Solaris Zones był bardzo drogi i zamknięty, a LXC i Docker od samego początku były otwartoźródłowe, co ułatwiło ich rozpowszechnienie.
Kontenery to “lepsza wirtualizacja”. Ale gdzie jest różnica? Żeby to wyjaśnić, popatrzmy na poniższy obrazek:
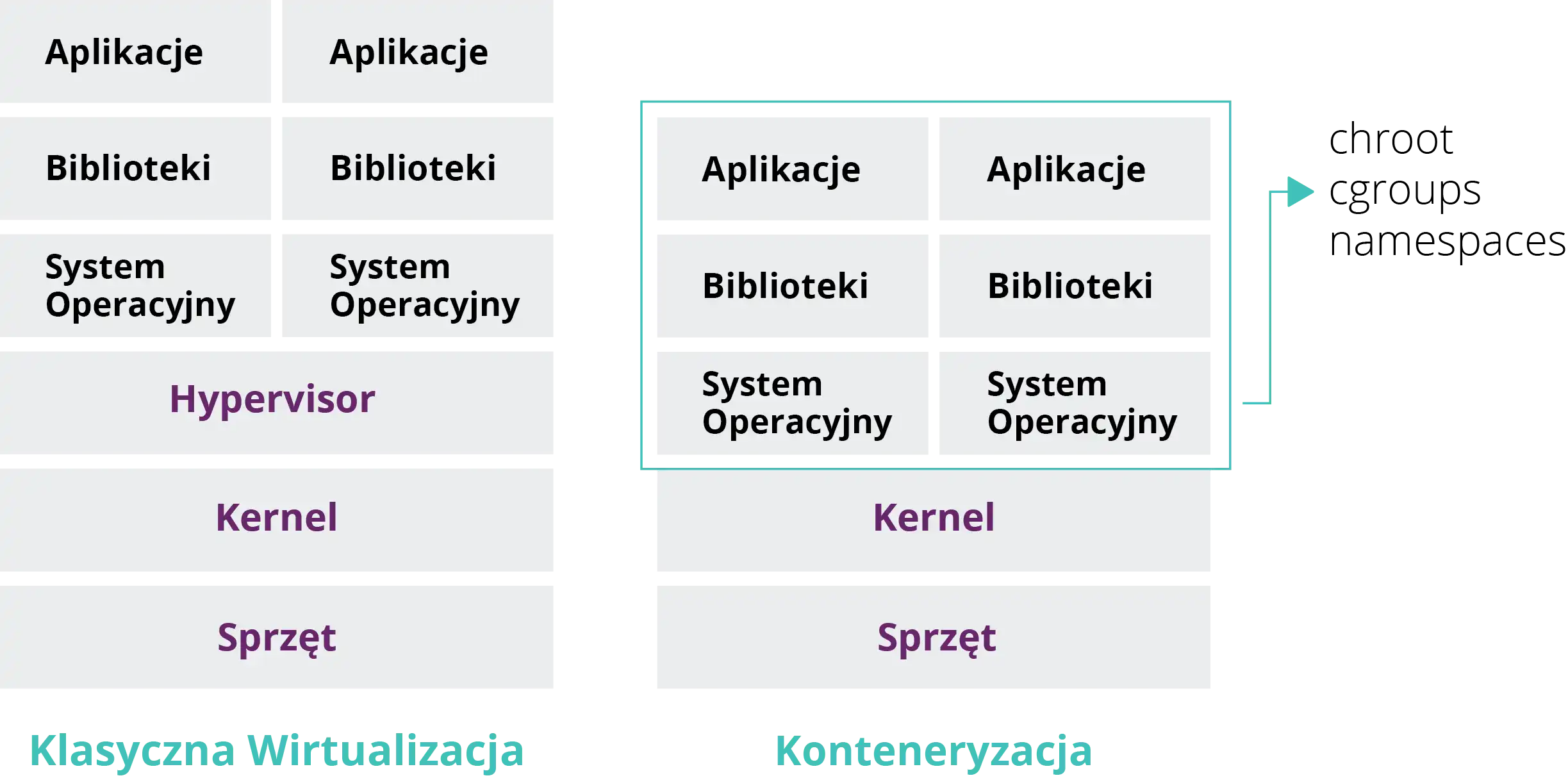
źródło: geeksforgeeks.pl
Jak widać w konteneryzacji pośrednictwo hypervisora zostało zastąpione przez namespace, które znajdują się w jądrze Linuksa (kernelu). Udostępniają one mechanizmy izolacji procesów i abstrakcję ”wirtualnego” sprzętu.
Jednym z podstawowych i pierwszych namespace były user, PID i network. PID namespace w zwykłym Linuksie pozwala uruchamiać wiele niezależnych drzew procesów naraz, w tym wiele tzw. PID 1 - zaczątków OS‑a (czyli jego wielokrotnego i równoległego uruchamiania na tej samej maszynie), user namespace, pozwala mieć wiele niezależnych rejestrów użytkowników/grup, a network namespace tworzy abstrakcję interfejsu sieciowego z oddzielnymi adresami IP. Powyższa kombinacja w dość sprawny sposób pozwala uruchamiać wiele kopii systemu operacyjnego, bez potrzeby posiadania hypervisora do wirtualnych maszyn.
Jak skrócić czas startu kontenera z kilkudziesięciu sekund do 100-200 milisekund? Wystarczy zmienić sposób zapisu obrazu dysku. Po pierwsze kontenery zajmują się tylko plikami, a nie całymi sektorami obrazu (czyli również wolnym miejscem). Po drugie używają overlay filesystems - system plików identyfikuje i zapisuje jedynie te z nich, które zostały zmodyfikowane. Trzecią częścią składową sukcesu jest fakt, że baza plikowa OS‑a jest dodana do zmian zrobionych na nim. Całość jest następnie skompresowana w obraz OS‑a i aplikacji. Zabiegi te pozwoliły na radykalne zmniejszenie obrazów kontenerów - z 3 GB w VM‑ce do 150 MB (w przypadku Ubuntu).
Redukcja rozmiarów obrazów kontenerowych przyczyniła się do zwiększenia ich dostępności i przenaszalności. Docker był od początku projektowany z towarzyszącym mu API, dlatego jedną z jego przewag był publiczny rejestr obrazów, co przyczyniło się do szybkiego rozwoju. Jako ciekawostkę mogę podać, że konkurencyjny koncept - LXC przyczynił się do powstania pierwszej na świecie publicznej platformy PaaS - Heroku.
Wraz z rosnącą popularnością Dockera, również z nim pojawiły się problemy. Znowu wyzwaniem stała się skala działania. Pojedyncze kontenery wiele organizacji intuicyjnie starało się podłączyć do systemd jako mechanizmu pilnującego. To rozwiązanie przestało się sprawdzać po przekroczeniu kilkunastu instancji kontenera. Aby temu zaradzić powstał Docker Swarm, który nie był jednak dopracowany i nie zyskał popularności.
Mimo niepowodzenia Docker Swarm spopularyzował pomysł cgroups, który polega na mierzeniu i limitowaniu namespace, a co za tym idzie kontenerów. Swarm, od bardzo wczesnego, stadium potrafił pokazać czytelne i użyteczne metryki kontenerów, co nie było wówczas powszechne w podobnych produktach.
Czas Kubernetes
Inżynierowie z Google pracujący nad nieznanym wówczas publicznie systemem Borg (nieprzypadkowe nawiązanie do serialu Star Trek), chcieli otworzyć koncept swojego systemu na świat. Dzięki wykorzystaniu doświadczenia i rozwiązań z Borg, Docker Swarm i innych podobnych platform, w 2014 roku została opublikowana pierwsza wersja Kubernetes. Google zapewnił zespół specjalistów, który rozwija kod, przy wykorzystaniu języka Go, nadaje też kierunek dalszemu rozwojowi tego projektu, w który włączyło się wiele innych firm i programistów.
Przytoczona historia jest niezwykła z jeszcze jednego punktu widzenia - jest to również opis zdarzeń, które przyczyniły się do eksplozji ruchu open source na świecie. Dostępność i powtarzalność narzędzi IT, które wytworzono w ciągu ostatnich lat jest wręcz zdumiewająca. W dzisiejszych czasach wiele przedsiębiorstw stara się mieć własne publiczne repozytoria kodu, albo kontrybuować do jakiegoś obiecującego projektu. Nawet firmy, które do tej pory “nie lubiły” otwartego źródła, w porę dostrzegły jego potencjał i dołączyły do tego ruchu. Tysiące miejsc pracy, kosmicznych projektów, startupów i firm powstało dzięki open source.
Przyjrzyjmy się kilku liczbom ze świata otwartych źródeł kodu (stan na dzień 26 listopada 2020 r.):
- projekt kernela Linuksa - 950 000 zmian, 16 000 kontrybutorów
- projekt Kubernetes - 95 000 zmian w repozytorium, 5800 kontrybutorów, 700 wypuszczonych wersji, i 107 000 ludzi na oficjalnym Slacku
- projekt Nix - 243 000 zmian, 6 000 kontrybutorów.
Liczba osób, które angażują się w tych projektach jest niesamowita! Tysiące programistów to rozmiar teamu IT, na który w jednym projekcie nie mogą sobie pozwolić nawet największe firmy. Tutaj jest właśnie widoczny ten fenomen - w zniesieniu limitów współpracy jest postęp. Wszystkie trzy wspomniane projekty są tak naprawdę wielkim eksperymentem ludzkości, który zmienił to jak pracuje się w grupach, niezależnie od tego czy jest się pracownikiem firmy, geograficznego położenia. Niejako zdjęliśmy wszystkie wcześniejsze ograniczenia miejsc pracy i wytwarzania kodu - i opłacało się!
W tym wpisie opowiedziałem jak rozwijały się kolejne technologie, które zdefiniowały świat automatyzacji procesów w IT i doprowadziły do powstania takich produktów jak m.in. Kubernetes. Sama technologia Kubernetes jest bardzo rozbudowana i zasługuje na oddzielny wpis, w którym wyjaśnię co konkretnie w środowisku IT ułatwia i dlaczego warto się nią zainteresować.