Era AI Act, czyli jak zapewnić bezpieczeństwo i compliance w systemach AI? Cloud for AI, część 2
W SKRÓCIE
Infrastruktura Cloud for AI gwarantuje suwerenność danych oraz uwzględnia zgodność z wymogami unijnego rozporządzenia AI Act dzięki wbudowaniu zaawansowanych mechanizmów bezpieczeństwa w każdą warstwę platformy. Rozwiązanie to skutecznie chroni przed nowymi typami zagrożeń, takimi jak prompt injection, jail breaking czy wycieki danych treningowych, wykorzystując m.in. NeuralTrust AI Firewall do detekcji anomalii oraz Federated Vector Store do rozproszenia architektury danych. Proces wdrażania innowacji wspierają narzędzia automatyzujące zgodność i etykę: Credo AI (raportowanie regulacyjne), AI Verify Toolkit (testy sprawiedliwości modeli) oraz Responsible AI Toolbox, który wprowadza niezbędną warstwę human-in-the-loop. Dzięki temu organizacje mogą łatwo adaptować się do zmieniających się przepisów, zachowując najwyższe standardy bezpieczeństwa w bezpiecznym środowisku chmurowym.
W poprzednim artykule opisaliśmy krajobraz rozwiązań AI dostępnych w chmurze publicznej Microsoft Azure, Google Cloud oraz OChK Stack – naszym nowym, autorskim rozwiązaniu zaprojektowanym z myślą o firmach, którym zależy na suwerenności technologicznej.
Z tej części dowiesz się:
- jakie są i czym charakteryzują się najnowsze zagrożenia dla systemów sztucznej inteligencji,
- w jaki sposób budować architekturę pod AI, by zapewnić swoim projektom bezpieczeństwo i zgodność z regulacjami,
- czym jest Cloud for AI i czym kierujemy się przy jej projektowaniu.
Artykuł, który właśnie czytasz, jest drugim z serii wpisów poświęconych zagadnieniom dotyczącym budowania rozwiązań AI w chmurze. Obserwuj nasz profil na LinkedIn, by nie przegapić kolejnej publikacji, a jeśli chcesz nadrobić poprzedni materiał, przejdź do artykułu: Gdzie tworzyć rozwiązania AI? Od globalnych gigantów do lokalnych liderów. Cloud for AI, część 1.
Cloud for AI: suwerenna infrastruktura AI
Współczesne organizacje stoją przed bezprecedensowym wyzwaniem połączenia ognia i wody: jak zbudować infrastrukturę AI, która będzie odporna na nowe, często nieprzewidywalne zagrożenia i jednocześnie zapewni zgodność z rosnącymi wymaganiami regulacyjnymi, pełną kontrolę nad danymi, najwyższą wydajność oraz niezbędną elastyczność? Dodatkowe utrudnienie dla zarządzania wdrożonymi już projektami stanowi tempo zmian – nowe wersje modeli, silników inferencji i bibliotek to dzisiaj często kwestia tygodni, a nawet dni.
Odpowiedzią na powyższe wyzwania jest Cloud for AI, budowane przez naszych ekspertów rozwiązanie bazujące na OChK Stack, które fundamentalnie zmienia sposób, w jaki organizacje podchodzą do wdrażania i zarządzania systemami sztucznej inteligencji.

Rys. 1: Kluczowe wartości Cloud for AI
Cloud for AI umożliwia skalowanie rozwiązań budowanych od pojedynczych stacji roboczych, poprzez środowiska on-premise, po chmurę publiczną. Skalowanie rozumiane jest w tym przypadku zarówno jako dynamiczne zwiększanie zasobów, jak i podejmowanie strategicznych decyzji dotyczących lokalizacji przetwarzania danych i modeli – łącznie ze scenariuszem hybrydowym, w którym komponenty mogą być rozproszone pomiędzy środowiskiem lokalnym a chmurą publiczną. Architektura Cloud for AI umożliwia obsługę projektów realizowanych zarówno w niewielkich zespołach, które wykorzystują pojedyncze GPU, jak i w środowiskach wielowęzłowych z setkami procesorów graficznych – bez konieczności ingerencji w kod projektu.
Istotnym założeniem projektowym Cloud for AI jest minimalizacja ryzyka związanego z tzw. vendor lock-in poprzez przyjęcie otwartego ekosystemu technologicznego, a także modułowość. Ta ostatnia umożliwia zarówno niezależny rozwój poszczególnych komponentów, jak i swobodny dobór technologii dopasowanych do specyficznych potrzeb użytkownika końcowego.
Budując Cloud for AI, bazowaliśmy na zebranych przez OChK wieloletnich doświadczeniach. To, co opisujemy niżej, nie jest kompletnym zestawem rozwiązań. To raczej „wierzchołek góry lodowej”, który pomoże Ci zrozumieć, w jaki sposób projektować infrastrukturę pod AI, by była bezpieczna i zgodna z przepisami.
Nowy krajobraz zagrożeń w systemach AI
Duże modele językowe (ang. Large Language Models, LLM) zrewolucjonizowały sposób, w jaki dzisiaj pracujemy z danymi i automatyzujemy procesy biznesowe. Modele, takie jak GPT-4, Claude czy Llama potrafią generować teksty, które ciężko odróżnić od tych pisanych przez człowieka, analizować dokumenty z niespotykaną dotąd precyzją i prowadzić złożone rozmowy.
Jednak rozwój sztucznej inteligencji przyniósł za sobą nie tylko nieograniczone możliwości, ale także zupełnie nowe kategorie zagrożeń, których skala i wyrafinowanie przekraczają wszystko, z czym mieliśmy do czynienia w tradycyjnej „odmianie" cyberbezpieczeństwa. Są one szczególnie groźne, ponieważ często wykorzystują fundamentalne właściwości systemów AI – ich zdolność do uczenia się, adaptacji i generalizacji. Wśród nich są, m.in.:
- Prompt injection – jedno z najpoważniejszych zagrożeń. Umożliwia atakującemu umieszczenie w dokumencie specjalnie spreparowanego tekstu, który po przetworzeniu przez model AI powoduje, że system zaczyna działać wbrew swoim pierwotnym instrukcjom. To jak włamanie do systemu, ale zamiast wykorzystywać błędy w kodzie, cyberprzestępca wykorzystuje sposób, w jaki model interpretuje język naturalny.
- Jailbreaking – technika obchodzenia zabezpieczeń modelu poprzez sprytne formułowanie pytań. Atakujący może, na przykład, poprosić model o napisanie historii o fikcyjnym hakerze, która w rzeczywistości będzie instrukcją włamywania się do systemów. Model, myśląc że tworzy fikcję, może ujawnić prawdziwe techniki hakerskie.
- Wycieki danych treningowych – zagrożenie, w którym modele językowe „zapamiętują" fragmenty danych, na których były trenowane. Odpowiednio spreparowane zapytanie może sprawić, że model odtworzy poufne informacje, które przypadkowo znalazły się w zbiorze treningowym.
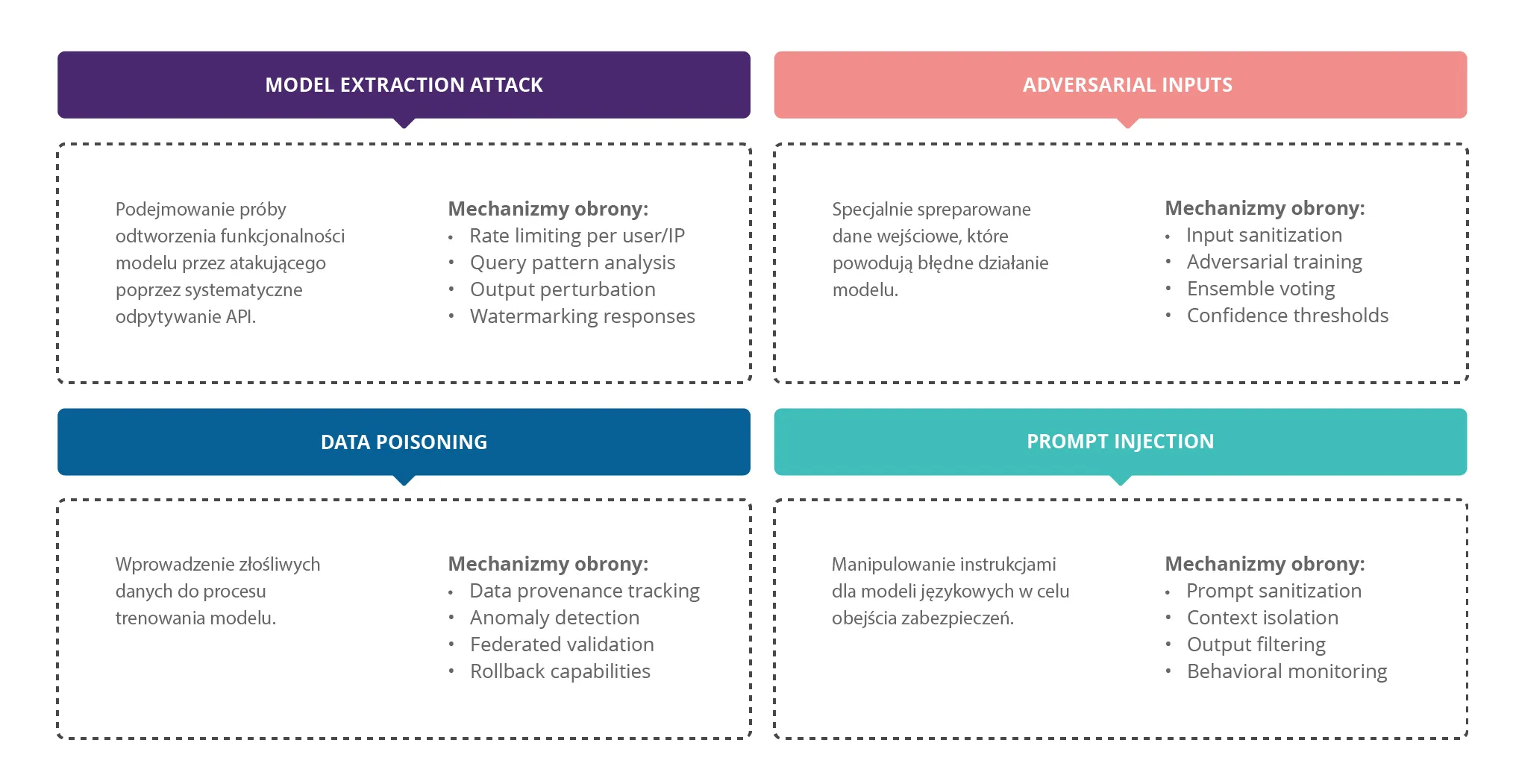
Rys. 2: Nowe kategorie zagrożeń dla bezpieczeństwa w erze AI
Przykład: Jak sklonować zamknięty model językowy krok-po-kroku?
1. API Reconnaissance i fingerprinting
Publicznie dostępne dokumentacje oraz fora programistyczne zdradzają, które endpointy zwracają same tokeny, a które pełne wartości logprobs, czyli informacje o prawdopodobieństwie wybrania danego tokena. Na tej podstawie można przygotować plan zapytań do modelu oraz oszacować koszty operacji, obliczane jako liczba przetworzonych tokenów pomnożona przez obowiązującą stawkę.
2. Masowe „wypożyczanie” kluczy
Setki kont deweloperskich zakładanych na skradzione lub odkupione tożsamości przejmują darmowe pule kredytów. W razie potrzeby atakujący kupują dodatkowe limity na szarej giełdzie lub korzystają z kart podarunkowych, dzięki czemu ruch nie wzbudza podejrzeń.
3. Fabryka promptów
Pipeline zbudowany na tańszym, otwartym modelu generuje miliony zróżnicowanych promptów (tłumaczenia, kod, instrukcje, diagnozy medyczne, wypowiedzi literackie). Każdy prompt trafia do modelu-nauczyciela (GPT-4) z temperaturą podniesioną tuż poniżej progu halucynacji, co zwiększa różnorodność danych wyjściowych.
4. Eksfiltracja wiedzy
W ciągu kilku tygodni powstaje baza, która zawiera dziesiątki miliardów tokenów odpowiedzi. Równolegle zapisywane są także top-k logity, czyli wartości odpowiadające k najbardziej prawdopodobnym tokenom. Te dane są kluczowe, ponieważ pozwalają później odtworzyć rozkład prawdopodobieństw modelu-nauczyciela. Aby nie przekroczyć limitów, ruch jest rozproszony na setki adresów IP i okna czasowe o niskim obciążeniu (na przykład godziny nocne).
5. Destylacja (trening studenta)
Zebranie mniej niż 6 mld tokenów i fine-tuning otwartego modelu (np. Yi-34B) na klastrze 256 × H800 wiąże się z kosztem około 6 milionów dolarów, co stanowi mniej więcej 1% budżetu niezbędnego do trenowania modelu od zera. Dodatkowo stosuje się technikę logit-matching, która polega na trenowaniu modelu-studenta w taki sposób, aby jego surowe, nieprzetworzone wyniki (czyli logity) były jak najbardziej zbliżone do logitów modelu referencyjnego (np. GPT-4).
6. Walidacja i ukrycie śladów
Wyniki referencyjne są porównywane offline – jeśli dywergencja (różnice) wyniesie więcej niż 8%, powtarzana jest runda promptowania tylko w obszarach, gdzie model-student wypada słabo (tzw. active error-seeding). Aby utrudnić wykrycie ingerencji, do zbioru danych dodaje się losowo mniej więcej 15% odpowiedzi modeli open-source, maskując stylistyczny „odcisk palca”.
Brzmi jak cyber-thriller albo prelekcja z Black Hat? Niestety, to nie fikcja. Właśnie tak – według zarzutów OpenAI oraz dostępnych, bardzo fragmentarycznych informacji – chińska firma DeepSeek zbudowała swój przełomowy model R1, destylując go z modeli OpenAI. Ta historia stała się jednym z najsłynniejszych w ciągu ostatnich lat przykładów, że „kradzież mózgu” modelu nie wymaga włamania do serwerowni – wystarczy karta kredytowa, trochę OSINT-u i dobrze napisany skrypt do promptowania.
Architektura bezpieczeństwa Cloud for AI
Cloud for AI pozwala uniknąć wielu zagrożeń dzięki wbudowaniu mechanizmów bezpieczeństwa w każdą warstwę platformy. Nie jest to dodatek czy nakładka, a fundamentalna część architektury.
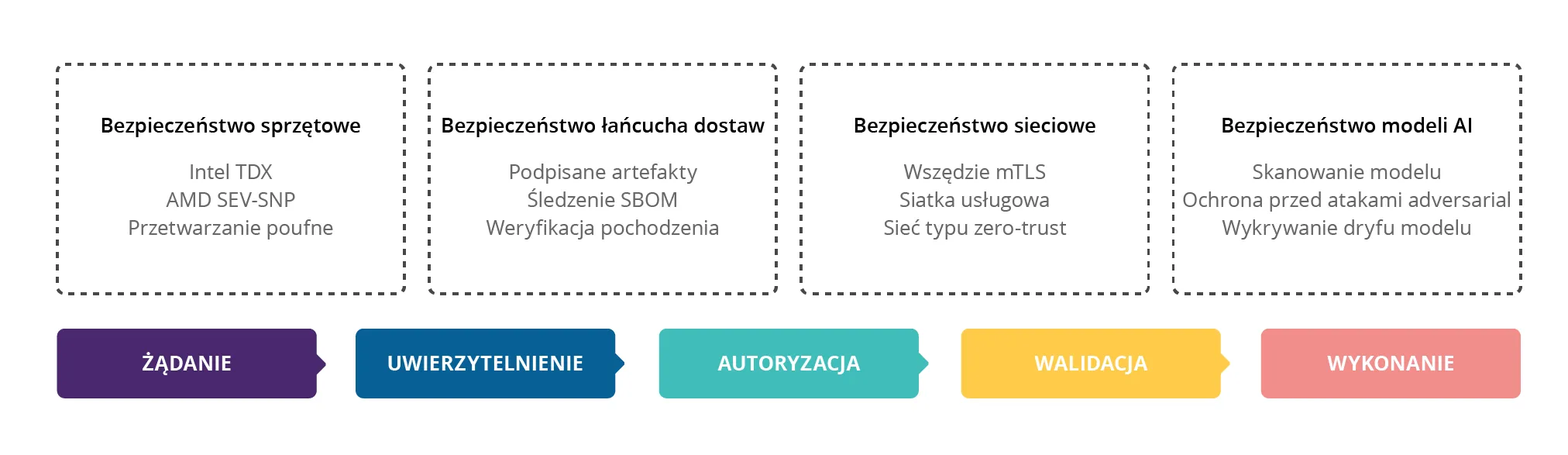
Rys. 3: Wielowarstwowa architektura bezpieczeństwa: model bezpieczeństwa zero-trust
NeuralTrust AI Firewall działa jak strażnik przy bramie, analizując każde zapytanie kierowane do modelu. Wykorzystuje zaawansowane techniki detekcji anomalii, aby rozpoznać próby wspomnianego już prompt injection czy jailbreaking. System klasyfikuje każde żądanie według trzech kategorii:
- Allow – zapytanie jest bezpieczne i może być przekazane do modelu,
- Transform – zapytanie wymaga modyfikacji przed przekazaniem (np. usunięcia potencjalnie niebezpiecznych fragmentów),
- Block - zapytanie jest jednoznacznie złośliwe i zostaje odrzucone.
Klasyfikacja odbywa się zgodnie z OWASP GenAI Top-10 – standardem bezpieczeństwa stworzonym specjalnie dla systemów generatywnej AI. Każda decyzja jest logowana i może być poddana audytowi, co zapewnia pełną zgodność z wymogami NIS2 dotyczącymi raportowania incydentów.
Z kolei Federated Vector Store to jedno z narzędzi, które wykorzystujemy do rozwiązania problemu bezpieczeństwa danych. Zamiast przechowywać wszystkie dane w jednym centralnym miejscu (co stanowiłoby łakomy kąsek dla hakerów), platforma wykorzystuje rozproszoną architekturę. Każdy tenant (najemca) ma swoją własną, odizolowaną instancję bazy wektorowej. Dane nigdy nie mieszają się między najemcami, a próba dostępu do cudzych danych jest strukturalnie niemożliwa.
Zapewnienie zgodności z AI Act i RODO
AI Act to nowe rozporządzenie unijne, które klasyfikuje systemy AI według czterech poziomów ryzyka: niedopuszczalne ryzyko, wysokie ryzyko, ograniczone ryzyko oraz minimalne ryzyko. Jako że większość zastosowań biznesowych AI mieści się w kategorii wysokiego lub ograniczonego ryzyka, AI Act wymaga od organizacji ponownego zaprojektowania całej architektury systemu, wprowadzając szereg obowiązków regulacyjnych, które powinny spełnić. Najważniejsze z nich obejmują:
- wdrożenie lub aktualizację systemu zarządzania ryzykiem w odniesieniu do systemów AI,
- zarządzanie danymi (data governance), w tym szczegółowy opis zbiorów treningowych oraz procesu ich walidacji,
- przygotowanie i utrzymywanie dokumentacji technicznej, która zawiera m.in. specyfikację algorytmów,
- rejestrowanie i monitorowanie zdarzeń w całym cyklu życia systemu AI.
Rozwiązanie Cloud for AI zostało zaprojektowane od podstaw z myślą o pełnej zgodności z AI Act. Co więcej, pozwala na łatwą adaptację do przyszłych przepisów, traktując zgodność regulacyjną nie jako jednorazowe wyzwanie, ale jako ciągły proces. Przedstawiamy przykładowe wykorzystywane rozwiązania:
- Credo AI automatyzuje tworzenie raportów zgodności, generując dokumentację w formacie SARIF (Static Analysis Results Interchange Format), standardzie używanym przez audytorów na całym świecie;
- AI Verify Toolkit przeprowadza automatyczne testy etyczności i sprawiedliwości modeli; dla każdego modelu klasyfikowanego jako wysokiego ryzyka, system automatycznie:
- testuje model pod kątem stronniczości względem różnych grup demograficznych,
- sprawdza, czy model nie dyskryminuje na podstawie chronionych cech,
- weryfikuje stabilność i przewidywalność odpowiedzi,
- generuje raporty zgodności w formacie wymaganym przez EU AI Act;
- Responsible AI Toolbox od Microsoft dodaje warstwę HITL (Human-in-the-Loop) dla krytycznych decyzji – system automatycznie kieruje nietypowe lub wysokiego ryzyka decyzje do weryfikacji przez człowieka, zapewniając zgodność z wymogiem ludzkiego nadzoru.

Rys. 4: AI Act-ready: compliance jako przewaga konkurencyjna
RODO wymaga z kolei, aby użytkownicy mieli prawo do usunięcia swoich danych. W kontekście AI jest to szczególnie trudne, ponieważ modele mogą „zapamiętać” informacje z danych treningowych. Cloud for AI rozwiązuje ten problem poprzez wykorzystanie narzędzi, takich jak:
- LakeFS – system wersjonowania danych działający jak „Git dla danych”. Każda zmiana w zbiorze danych jest śledzona, a usunięcie danych użytkownika powoduje automatyczne utworzenie nowej wersji datasetu bez tych informacji;
- DVC (Data Version Control) – uzupełnia LakeFS o śledzenie zmian w przetworzonych cech. Gdy użytkownik żąda usunięcia swoich danych, system może cofnąć się do wersji sprzed dodania tych danych i przetrenować model od tego punktu;
- Synthcity – generator danych syntetycznych, który pozwala testować systemy bez użycia prawdziwych danych osobowych; szczególnie przydatny przy testach obciążeniowych i weryfikacji bezpieczeństwa.
Podsumowanie
Jednym z największych wyzwań przy projektowaniu architektury pod implementację sztucznej inteligencji jest ochrona przed zagrożeniami, których jeszcze nie znamy. Systemy AI, szczególnie te, które bazują na dużych modelach językowych, mogą rozwijać niespodziewane zdolności, tzw. emergent capabilities. Właśnie dlatego tak istotne jest, aby środowiska pod projekty AI budować w sposób świadomy i przewidywalny. Cloud for AI, stworzone przez ekspertów OChK, pozwala uniknąć wielu zagrożeń „nowej generacji”, takich jak prompt injection czy jailbreaking, a także dostosować się do tych, które dopiero powstaną.
Wiesz już, w jaki sposób zaprojektowaliśmy architekturę bezpieczeństwa Cloud for AI, by nie tylko chronić ją przed cyberatakami, ale także by spełnić wymogi AI Act i RODO. W kolejnym artykule zdradzimy, jakie rozwiązania zastosowaliśmy, aby odpowiedzieć na wyzwania systemów AI – nieprzewidywalność obciążenia, konieczność błyskawicznego skalowania, ciągłe zmiany w krajobrazie modeli i bibliotek, wymogi dotyczące latencji mierzonej w milisekundach, oraz potrzeba pełnej kontroli nad danymi i modelami.
Jeśli chcesz już teraz dowiedzieć się więcej o Cloud for AI, zapraszamy do kontaktu.