W SKRÓCIE
Budowanie infrastruktury pod AI powinno uwzględniać zarówno filozofię AI-first infrastructure, która wspiera sposób działania systemów bazujących na LLMach, ale także odpowiednią dozę niezależności technologicznej, która umożliwia swobodne dobieranie i wymienianie technologii na taką, która nadąża za potrzebami. Narzędzia, które warto zastosować w tym procesie uwzględniają m.in. Ray Serve (który pełni rolę inteligentnego routera), vLLM (silnik inferencji nowej generacji) i MAX (silnik dla języka Mojo, zaprojektowanego specjalnie dla AI). Efektywne wykorzystanie kart graficznych możliwe jest zaś dzięki KubeRay, Gang Scheduling i OpenCost. W uniknięciu efektu vendor lock-in pomaga z kolei Crossplane, kontroler, który pozwala zarządzać zasobami u różnych dostawców chmury przez jednolite API, a także możliwość integracji Modular MAX Engine (MAX). Wszystkie wspomniane narzędzia stanowią fundament Cloud for AI – autorskiego rozwiązania OChK.
Jednym z najczęstszych błędów przy wdrażaniu rozwiązań AI jest traktowanie ich jak rozwinięcie bądź uzupełnienie dotychczasowych rozwiązań. Tymczasem infrastruktura dla systemów, które będą bazować na dużych modelach językowych, rządzi się zupełnie innymi prawami. W tym przypadku liczy się nie tylko kwestia wyboru odpowiednich modeli i danych, ale przede wszystkim zaprojektowanie środowiska w taki sposób, aby mogło nadążyć za tempem rozwoju technologii, nagłymi i bardzo zmiennymi obciążeniami, a jednocześnie dało zespołowi pełną kontrolę nad tym, co faktycznie dzieje się „pod maską”.
Jak zbudować infrastrukturę, która poradzi sobie z wyzwaniami, jakie stawiają nam systemy AI? Z tego artykułu dowiesz się, jakimi założeniami się kierować i z jakich technologii skorzystać, by z powodzeniem zaprojektować architekturę AI-ready, czyli w pełni przygotowaną na rozwijanie nowoczesnych rozwiązań sztucznej inteligencji.
Artykuł, który właśnie czytasz, jest trzecim z serii wpisów poświęconych zagadnieniom dotyczącym budowania rozwiązań AI w chmurze. Wiesz już, gdzie rozwijać projekty AI i za pomocą jakich narzędzi. Znasz także założenia tytułowego Cloud for AI i kilka kluczowych zasad budowania architektury, które pomogą Ci rozwijać projekty bezpiecznie i zgodnie z regulacjami, takimi jak AI Act i RODO.
To jeszcze nie koniec serii. Obserwuj nasz profil na LinkedIn, by nie przegapić kolejnej publikacji!
Czym charakteryzuje się infrastruktura AI-ready?
Budowanie infrastruktury dla systemów sztucznej inteligencji to nie kolejny etap ewolucji dotychczasowych rozwiązań, ale prawdziwa rewolucja w projektowaniu i zabezpieczaniu środowiska. Przede wszystkim dlatego, że musi ono sprostać wyzwaniom, takim jak nieprzewidywalne obciążenia, konieczność błyskawicznego skalowania, ciągłe zmiany w ekosystemie modeli i bibliotek, ultra niska latencja oraz pełna kontrola nad danymi i modelami.
Dodatkowo jednym z częstych problemów, z jakimi mierzą się organizacje, które wdrażają systemy AI, jest tzw. vendor lock-in. Uzależnienie się od jednego dostawcy technologii, szczególnie w kontekście AI, z czasem okazuje się kosztowne – zarówno pod względem technologicznym, jak i finansowym. Ogranicza także elastyczność i utrudnia modernizację. Warto więc projektować środowisko w sposób, który maksymalnie tę zależność redukuje.
Cloud for AI, rozwiązanie OChK zaprojektowane zgodnie z zasadą: „prawie każdy komponent jest wymienny”, umożliwia swobodne dobieranie i wymienianie poszczególnych elementów infrastruktury bez konieczności przebudowywania całego środowiska. Jak to działa w praktyce? Wyobraź sobie platformę AI jako zbiór klocków LEGO. Jeśli każdy klocek (komponent) ma standardowe złącza, może zostać łatwo zastąpiony innym, który pełni podobną funkcję. Przykładowo, jeżeli dziś korzystasz z vLLM jako silnika inferencyjnego, a za pół roku pojawi się alternatywa, która jest bardziej wydajna, Cloud for AI umożliwi Ci jej wdrożenie bez modyfikowania pozostałych warstw systemu. Taka modułowość ma kluczowe znaczenie w środowiskach, w których cykl życia modeli zmienia się nie w skali lat, lecz miesięcy, a czasem nawet tygodni.
Cloud for AI to rozwiązanie kompatybilne zarówno z technologiami otwartymi, jak i komercyjnymi. Dzięki temu organizacje zyskują pełną swobodę podczas budowania własnego ekosystemu narzędzi i usług, mogąc łączyć je w sposób najlepiej dopasowany do swoich aktualnych potrzeb i celów. Takie podejście nie tylko zwiększa elastyczność operacyjną, ale także pozwala budować przewagę konkurencyjną w tempie, jakie narzuca rozwijający się świat sztucznej inteligencji.
Poniżej znajdziesz omówienie wybranych narzędzi i dobrych praktyk, które zastosowaliśmy w ramach Cloud for AI i które mogą stanowić fundament dobrze zaprojektowanej infrastruktury, gotowej do rozwoju systemów sztucznej inteligencji.
Filozofia AI-First Infrastructure
Tradycyjne podejście do infrastruktury traktuje sztuczną inteligencję jak kolejne obciążenie (ang. workload), które trzeba po prostu obsłużyć. To błąd, który może się na Tobie szybko zemścić – zwłaszcza gdy próbujesz udostępniać model dużej liczbie użytkowników. Obciążenia generowane przez systemy AI mają unikalne właściwości, których nie da się sprowadzić do standardowych wzorców.
Przede wszystkim warto podkreślić, że AI-first nie oznacza jedynie uruchamiania dużych modeli. To projektowanie całej architektury w taki sposób, aby wspierała sposób działania systemów, które bazują na dużych modelach językowych (ang. Large Language Models, LLM): planowanie, rozumowanie i wykonywanie zadań w czasie rzeczywistym. Gdy w grę wchodzą agenci – czyli modele sterujące innymi narzędziami – oraz zaawansowane techniki rozumowania (np. Chain-of-Thought, Tree-of-Thought, ReAct, SARSA-RLHF), pojawiają się zupełnie nowe wektory obciążenia i wyzwania, które trzeba wziąć pod uwagę już na etapie projektowania architektury.
Obciążenie generowane przez modele AI nie jest stałe. Charakteryzuje je wzorzec nagłych skoków zapotrzebowania na moc obliczeniową (ang. burst compute patterns). Model może pozostawać przez wiele godzin w uśpieniu, by w ciągu kilku minut potrzebować teraflopsów mocy. Tradycyjna infrastruktura w takim scenariuszu często działa nieefektywnie – albo przewymiarowuje zasoby i marnuje je przez większość czasu (ang. over-provisioning), albo nie jest w stanie obsłużyć nagłych pików obciążenia (ang. under-provisioning). Sytuację dodatkowo komplikuje fakt, że agent potrafi wykonać kilka lub kilkadziesiąt kroków w cyklu planowania i działania (plan → narzędzie → obserwacja → modyfikacja planu), a każdy taki krok generuje kolejny impuls zapotrzebowania na zasoby.
W przeciwieństwie do klasycznych aplikacji, gdzie zasoby obliczeniowe i pamięć można skalować niezależnie, obciążenia AI wymagają ścisłej współzależności tych dwóch elementów (ang. memory-compute coupling). Model o wielkości 70 miliardów parametrów potrzebuje nie tylko odpowiedniej mocy GPU, lecz przede wszystkim pamięci o wysokiej przepustowości. Oprócz samej pamięci modelu trzeba również uwzględnić pamięć stanu każdego agenta – kontekstu, planów, ścieżki rozumowania czy wyników.
Kolejnym istotnym aspektem jest wrażliwość na opóźnienia (ang. latency sensitivity). Różnica między 50 a 500 milisekundami może decydować o tym, czy użytkownicy uznają system za użyteczny. Odpowiedzi w czasie rzeczywistym wymagają nie tylko szybkich GPU (procesorów graficznych), ale też starannie zoptymalizowanej ścieżki przetwarzania – od momentu przyjęcia żądania po wygenerowanie odpowiedzi.
Wreszcie, zarówno modele AI, jak i dane, które przetwarzają, tworzą swoiste studnie grawitacyjne (ang. gravity wells). Przenoszenie terabajtów wag modeli pomiędzy lokalizacjami jest kosztowne i czasochłonne, dlatego architektura musi uwzględniać lokalizację modeli i danych w decyzjach o rozmieszczeniu i skalowaniu. Nie można też zapominać o tzw. „grawitacji stanu” – agenci generują i konsumują dynamiczne stany, takie jak bazy epizodyczne czy pamięci podręczne kolejnych kroków planowania.
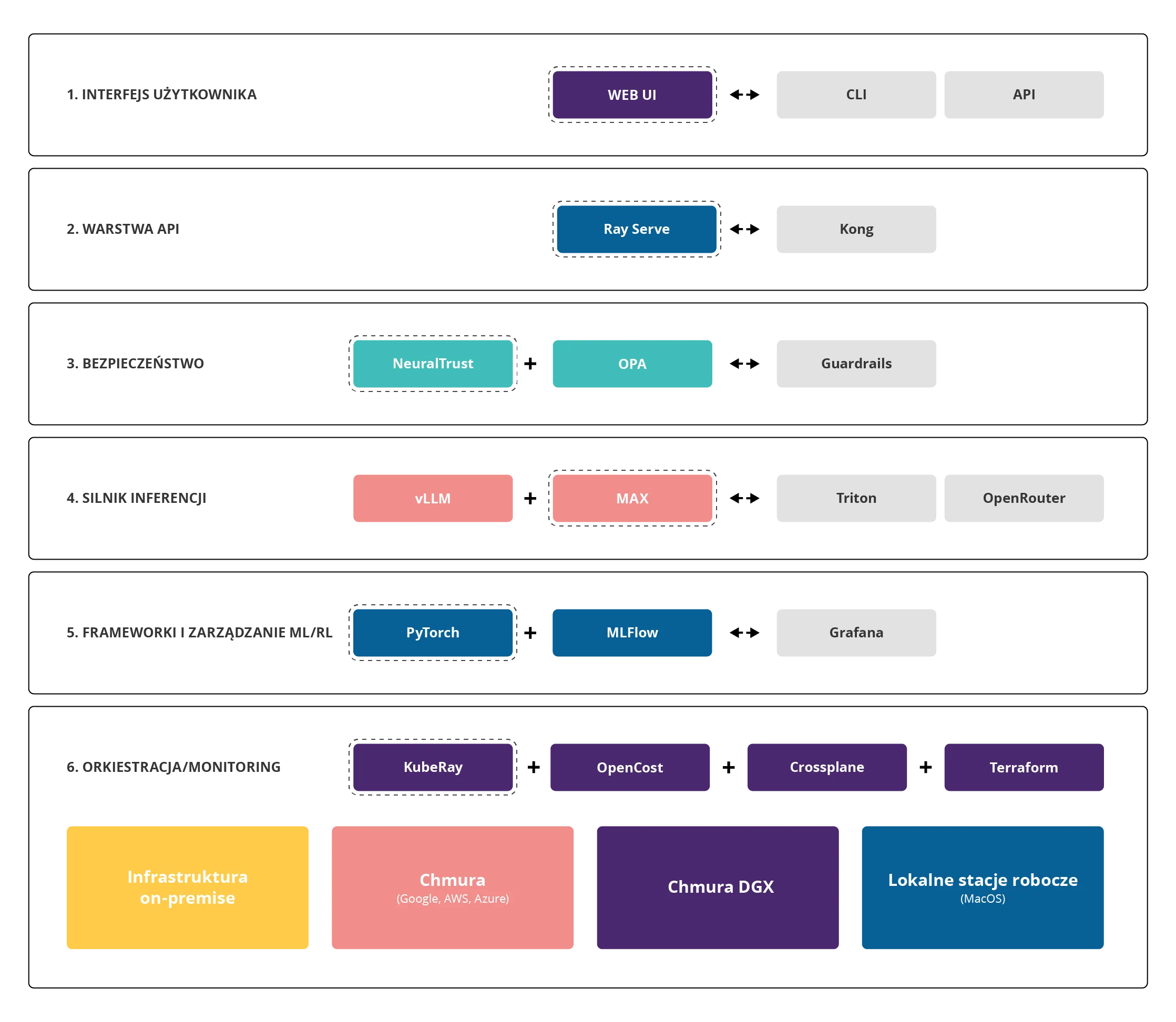
Rys. 1: Architektura Cloud for AI
Warstwa inferencji, czyli serce systemu
Warstwa inferencji to miejsce, w którym „dzieje się cała magia", tzn. modele AI faktycznie generują odpowiedzi. Cloud for AI wykorzystuje tu kilka kluczowych technologii:
- Ray Serve – pełni rolę inteligentnego routera. Jest jak doświadczony dyspozytor w centrali telefonicznej – przyjmuje zapytania przychodzące i kieruje je do odpowiedniego podsystemu. Co ważne, Ray Serve monitoruje obciążenie i automatycznie uruchamia dodatkowe instancje modeli, gdy ruch się zwiększa. Jeśli latencja P95 (czas odpowiedzi dla 95% zapytań) przekroczy 150 milisekund, system automatycznie skaluje się w górę.
- vLLM (Versatile Large Language Model) – to silnik inferencji nowej generacji. Wykorzystuje technikę PagedAttention, która pozwala efektywnie zarządzać pamięcią GPU. Aby lepiej zrozumieć jego działanie, wyobraź sobie, że GPU to bardzo szybki, ale ograniczony magazyn. vLLM organizuje ten magazyn tak sprytnie, że zwiększa jego pojemność o 2-3 razy. Rezultat? Model Llama-3 70B osiąga przepustowość ponad 1000 tokenów na sekundę – to jak generowanie całej strony tekstu w ułamku sekundy.
- MAX (Modular Accelerated Xecution) – to silnik stworzony dla języka Mojo, nowego języka programowania zaprojektowanego specjalnie dla AI. MAX błyszczy w zadaniach, które wymagają niestandardowych optymalizacji i osiąga imponującą wydajność w konfiguracji wielowęzłowej. Co ważne, jest również kompatybilny z Pythonem – oprogramowanie stworzone w Pythonie działa „od ręki”.
- Triton – mamy też coś dla tradycjonalistów, którzy stawiają na rozwiązania od NVIDII dla tego obszaru 😉
Inteligentne zarządzanie zasobami
Karty graficzne (GPU) to najdroższy element infrastruktury AI. Pojedyncza karta H200/H100 kosztuje dziesiątki tysięcy euro. Cloud for AI traktuje GPU jak cenny zasób, który musi być wykorzystywany w możliwie najbardziej efektywny sposób. Aby osiągnąć ten cel, wykorzystujemy narzędzia, takie jak:
- KubeRay – wprowadza rewolucyjną koncepcję współdzielenia GPU, tzn. zamiast przydzielać całą kartę graficzną jednemu zadaniu (które może wykorzystywać tylko 25% jej mocy), system dzieli GPU na mniejsze części.
- Gang Scheduling – zapewnia, że wszystkie części rozproszonego zadania startują jednocześnie. To krytyczne dla dużych modeli, które muszą być podzielone między wiele GPU. Bez tego mechanizmu, część GPU mogłaby czekać bezczynnie na pozostałe, marnując cenne zasoby.
- OpenCost – dostarcza szczegółową analizę kosztów w czasie rzeczywistym. Każda logiczna grupa zasobów (ang. namespace) ma przypisany licznik kosztów. Menedżerowie mogą zobaczyć na żywo, ile kosztuje każde zapytanie do modelu, każde trenowanie, każda operacja. To jak licznik taksówki dla AI – zawsze wiesz, ile płacisz.
Pipeline danych. Od surowych danych do działającego modelu
Proces przekształcania surowych danych w działający model AI można porównać do linii produkcyjnej w fabryce – każdy etap musi być precyzyjnie zorganizowany. Poniżej znajdziesz przykład pipeline'u, który pokazuje, że nawet proste wystawienie modelu dla użytkownika końcowego nie jest takie proste jak się wydaje. Podane rozwiązania dla każdego etapu są przykładowe. Pamiętaj o ważnej zasadzie, która stoi za Cloud for AI – jej „klocki LEGO” możesz dobierać w zależności od potrzeb:
1. Ingest (Pobieranie) - Vector.dev zastępuje tradycyjne narzędzia takie jak Fluent-Bit, oferując transformacje WASM, pozwalając na czyszczenie i przekształcanie danych już w momencie ich pobierania.
2. Validate (Walidacja) - Great Expectations sprawdza jakość danych, a system definiuje „kontrakty", czyli zasady, które muszą spełniać dane (np. „pole wiek musi być liczbą między 0 a 150"). Dane, które nie spełniają kontraktów, zostają odrzucone.
3. Commit (Zatwierdzanie) - LakeFS tworzy niezmienną migawkę danych. Każda wersja otrzymuje unikalny identyfikator, co pozwala zawsze wrócić do konkretnego stanu danych.
4. Feature Engineering - Kubeflow Pipelines orkiestruje przekształcanie surowych danych w cechy (ang. features) używane przez modele. To jak przygotowanie składników przed gotowaniem – dane są czyszczone, normalizowane, łączone.
5. Training (Trenowanie) - KubeRay zarządza rozproszonym trenowaniem na wielu GPU. Duże modele są automatycznie dzielone między karty graficzne, a system synchronizuje proces uczenia.
6. Governance (Zarządzanie) - Credo AI i AI Verify przeprowadzają testy etyczności i generują raporty zgodności. Każdy model otrzymuje „paszport", który dokumentuje jego pochodzenie i cechy szczególne.
7. Package (Pakowanie) - Modele są kompilowane (Mojo/MAX) i cyfrowo podpisywane (Cosign). To gwarantuje, że w produkcji działa dokładnie ten sam model, który przeszedł testy.
8. Serve (Serwowanie) - Ray Serve udostępnia model przez API, automatycznie skalując liczbę instancji według obciążenia.
9. Observe (Monitorowanie) - System zbiera metryki wydajności, wykrywa drift (zmianę charakterystyki danych) i alarmuje o anomaliach.
Multicloud jako standard
Wiesz już, że tzw. vendor lock-in to zmora współczesnego rynku IT. Cloud for AI wykorzystuje Crossplane, kontroler, który pozwala zarządzać zasobami u różnych dostawców chmury przez jednolite API.
W praktyce oznacza to, że ten sam manifest YAML może utworzyć klaster GPU w AWS, Azure, Google Cloud lub nVidia GDX Liptron. Migracja między dostawcami to kwestia zmiany kilku parametrów, nie przepisywania całego systemu. To daje prawdziwą niezależność i siłę negocjacyjną wobec dostawców.
MAX Engine jako game changer
W tym kontekście warto wspomnieć także o integracji Modular MAX Engine (MAX), który jest jednym z kluczowych elementów Cloud for AI.
CUDA (ang. Compute Unified Device Architecture) stało się w praktyce standardem w branży, ale oznacza to całkowite uzależnienie od firmy NVIDIA. MAX przełamuje ten monopol, kompilując modele do uniwersalnej pośredniej reprezentacji, która następnie może zostać zoptymalizowana pod dowolne środowisko sprzętowe:
- karty graficzne NVIDIA (bez konieczności korzystania z CUDA),
- karty graficzne AMD (natywne wsparcie dla ROCm),
- karty graficzne Intel i akceleratory Gaudi,
- układy Apple Silicon,
- egzotyczne akceleratory, takie jak Cerebras czy Graphcore.
Co ciekawe, MAX często osiąga lepszą wydajność niż natywne implementacje. Dlaczego tak się dzieje? Ponieważ może stosować optymalizacje, które w ogólnych frameworkach – takich jak PyTorch – nie są możliwe:
- łączenie operacji (ang. kernel fusion) na poziomie całego modelu,
- eliminacja zjawiska zbędnego kopiowania danych w pamięci,
- optymalizacje specyficzne dla danego sprzętu (np. wykorzystanie rdzeni tensorowych czy specjalizowanych jednostek macierzowych).
Dodatkowo, taka warstwa abstrakcji nie oznacza pogorszenia wydajności. MAX pokazuje, że można osiągnąć odpowiednią przenośność bez żadnych kompromisów.
Podsumowanie
To, w jaki sposób zaprojektujesz infrastrukturę AI-ready, ma bezpośredni wpływ na efektywność budowanych rozwiązań. Dlatego tak istotne jest, by mieć świadomość, czym różni się ona od dobrze znanych środowisk oraz jakie technologie i podejścia warto zastosować, aby skutecznie odpowiedzieć na specyficzne wyzwania, jakie stawia sztuczna inteligencja.
Rozwiązanie Cloud for AI, które nasi eksperci budują na bazie OChK Stack, reprezentuje fundamentalną zmianę w myśleniu o infrastrukturze – zostało od podstaw zaprojektowane z myślą o wymaganiach systemów AI. Łączy technologie otwarte, które można elastycznie dobierać w zależności od potrzeb, z architekturą niezależną sprzętowo, dzięki czemu nie ogranicza wyboru platform czy dostawców. Cloud for AI odpowiada na wymogi regulacyjne, takie jak AI Act, i zapewnia pełną kontrolę nad przetwarzanymi danymi, co ma kluczowe znaczenie w kontekście ich bezpieczeństwa. Działa w dowolnym środowisku – od stacji roboczej, przez własną serwerownię, aż po chmurę – pozwalając precyzyjnie planować i kontrolować koszty na każdym etapie wdrożenia.
Jeśli masz pytania dotyczące budowania infrastruktury AI-ready, chcesz omówić z nami własne plany wdrażania AI lub chcesz dowiedzieć się więcej o Cloud for AI, zapraszamy do kontaktu.